友情支持
如果您觉得这个笔记对您有所帮助,看在D瓜哥码这么多字的辛苦上,请友情支持一下,D瓜哥感激不尽,😜
|
|


有些打赏的朋友希望可以加个好友,欢迎关注D 瓜哥的微信公众号,这样就可以通过公众号的回复直接给我发信息。

公众号的微信号是: jikerizhi。因为众所周知的原因,有时图片加载不出来。 如果图片加载不出来可以直接通过搜索微信号来查找我的公众号。 |
139. 单词拆分
给你一个字符串 s 和一个字符串列表 wordDict 作为字典。如果可以利用字典中出现的一个或多个单词拼接出 s 则返回 true。
注意:不要求字典中出现的单词全部都使用,并且字典中的单词可以重复使用。
示例 1:
输入: s = "leetcode", wordDict = ["leet", "code"] 输出: true 解释: 返回 true 因为 "leetcode" 可以由 "leet" 和 "code" 拼接成。
示例 2:
输入: s = "applepenapple", wordDict = ["apple", "pen"]
输出: true
解释: 返回 true 因为 "applepenapple" 可以由 "apple" "pen" "apple" 拼接成。
注意,你可以重复使用字典中的单词。
示例 3:
输入: s = "catsandog", wordDict = ["cats", "dog", "sand", "and", "cat"] 输出: false
提示:
-
1 <= s.length <= 300 -
1 <= wordDict.length <= 1000 -
1 <= wordDict[i].length <= 20 -
s和wordDict[i]仅由小写英文字母组成 -
wordDict中的所有字符串 互不相同
思路分析
回溯+备忘录:
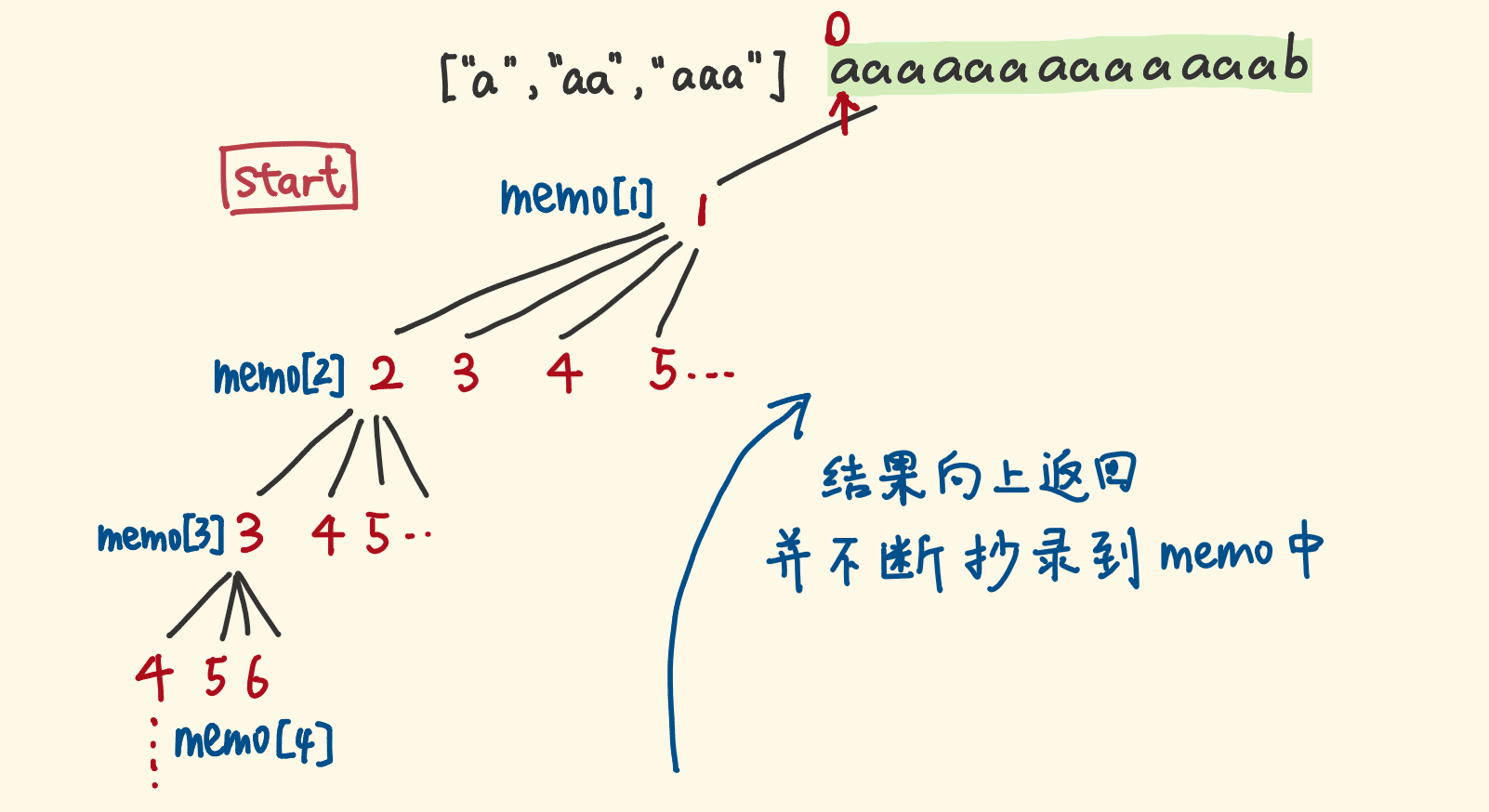
动态规划


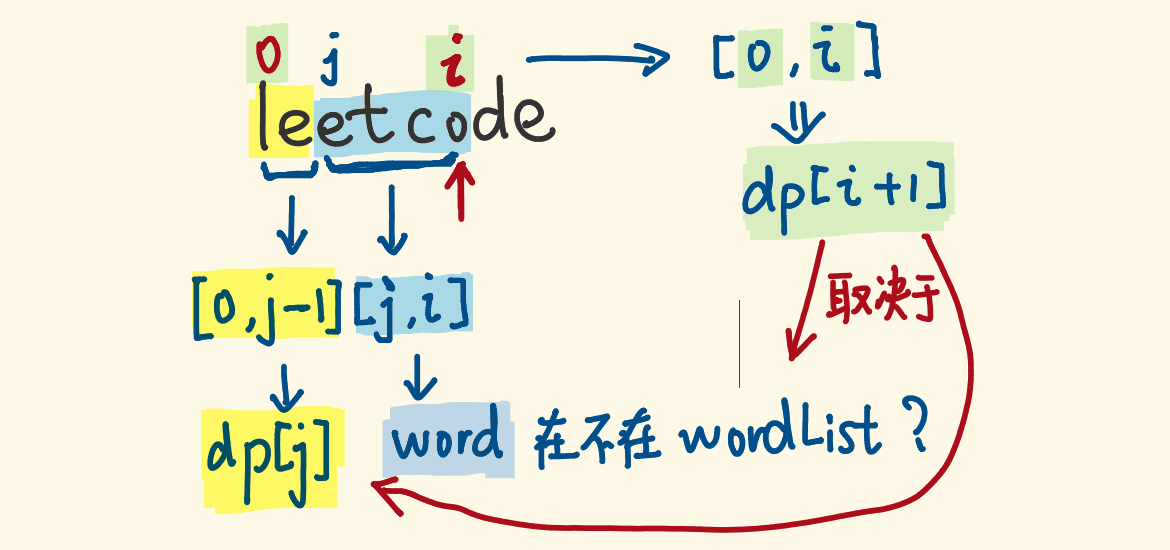
我的思路:
\(dp[i+j] = dp[i] \& (s[i, i+j] \in dict)\)
从 \(0\) 到 \(i\) 已经确定。从当前位置 \(i\) 向前推进到 \(i+j\),其中 \(j\) 是某个一个单词的长度。
动态规划。有两种思路:①向后看,从当前位置截取 word 长度的子串,判断子串和当前 word 是否相等以及之前的字符串是否可以可以拆分;②向前进,从零开始,根据当前 word 的长度,在同等长度子串相等的情况下,向前设置子串可以拆分,直到结尾。
-
一刷
-
二刷(回溯+备忘录)
-
二刷(动态规划)
-
三刷
-
四刷
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
/**
* Runtime: 11 ms, faster than 6.65% of Java online submissions for Word Break.
*
* Memory Usage: 44.3 MB, less than 5.08% of Java online submissions for Word Break.
*
* Copy from: https://leetcode-cn.com/problems/word-break/solution/dan-ci-chai-fen-by-leetcode/[单词拆分 - 单词拆分 - 力扣(LeetCode)]
*
* @author D瓜哥 · https://www.diguage.com
* @since 2020-01-24 09:39
*/
public boolean wordBreak(String s, List<String> wordDict) {
boolean[] dp = new boolean[s.length() + 1];
Arrays.fill(dp, false);
dp[0] = true;
Set<String> dict = new HashSet<>(wordDict);
for (int i = 1; i <= s.length(); i++) {
for (int j = 0; j < i; j++) {
if (dp[j] && dict.contains(s.substring(j, i))) {
dp[i] = true;
break;
}
}
}
return dp[s.length()];
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
/**
* 纯回溯通过 34/47 的测试用例。在 35 个测试用例时超时。
*
* 加备忘录则可以通过。效率还挺高,时间和内存都超过了 80%+ 的用户
*
* @author D瓜哥 · https://www.diguage.com
* @since 2025-04-19 15:41:59
*/
public boolean wordBreak(String s, List<String> wordDict) {
Set<Integer> wordLengths = new HashSet<>();
for (String string : wordDict) {
wordLengths.add(string.length());
}
Set<String> set = new HashSet<>(wordDict);
List<Integer> lengths = wordLengths.stream()
.sorted(Comparator.reverseOrder()).toList();
// 备忘录:记录剩余 i 个字符时,字符串是否可以拆分
Boolean[] memo = new Boolean[s.length()];
return backtrack(s, set, lengths, memo);
}
private boolean backtrack(String s, Set<String> set,
List<Integer> lengths, Boolean[] memo) {
if (s == null || s.isEmpty() || set.contains(s)) {
return true;
}
if (s.length() < lengths.getLast()) {
return false;
}
for (Integer i : lengths) {
if (s.length() < i) {
continue;
}
String prefix = s.substring(0, i);
if (!set.contains(prefix)) {
continue;
}
String substring = s.substring(i);
if (memo[substring.length() - 1] != null) {
return memo[substring.length() - 1];
}
boolean track = backtrack(substring, set, lengths, memo);
memo[substring.length() - 1] = track;
if (track) {
return true;
}
}
return false;
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
/**
* @author D瓜哥 · https://www.diguage.com
* @since 2025-04-19 17:13:31
*/
public boolean wordBreak(String s, List<String> wordDict) {
boolean[] dp = new boolean[s.length() + 1];
dp[0] = true;
for (int i = 0; i < s.length(); i++) {
// 如果前 i 个字符不能被拆分,则跳过该情况
if (!dp[i]) {
continue;
}
for (String word : wordDict) {
int wordLen = word.length();
if (s.length() < i + wordLen) {
continue;
}
// 如果已经确认可以拆分,则跳过
if (dp[i + wordLen]) {
continue;
}
String substring = s.substring(i, i + wordLen);
// dp[i+length] = dp[i] && s[i, i+length]∈dict
dp[i + wordLen] = dp[i] && word.equals(substring);
}
}
return dp[s.length()];
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
/**
* @author D瓜哥 · https://www.diguage.com
* @since 2025-11-05 21:17:21
*/
public boolean wordBreak(String s, List<String> wordDict) {
boolean[] dp = new boolean[s.length() + 1];
dp[0] = true;
for (int i = 1; i <= s.length(); i++) {
for (String word : wordDict) {
if (i < word.length()) {
continue;
}
dp[i] = dp[i - word.length()]
&& word.equals(s.substring(i - word.length(), i));
if (dp[i]) {
break;
}
}
}
return dp[s.length()];
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
/**
* @author D瓜哥 · https://www.diguage.com
* @since 2025-12-23 11:42:22
*/
public boolean wordBreak(String s, List<String> wordDict) {
boolean[] dp = new boolean[s.length() + 1];
dp[0] = true;
for (int i = 0; i <= s.length(); i++) {
if (!dp[i]) {
continue;
}
for (String word : wordDict) {
if (i + word.length() <= s.length()
&& !dp[i + word.length()]
&& word.equals(s.substring(i, i + word.length()))) {
dp[i + word.length()] = true;
}
if (dp[s.length()]) {
return true;
}
}
}
return dp[s.length()];
}